The worst nightmare of analytics managers is accidentally blowing up the data warehouse (DWH) cost. This could happen by accidentally running a query that scans the entire raw table that is huge. Even when the table is not at the petabyte scale, the accumulation of repeated queries could add up to.
The above scenario is especially true when you are using BigQuery, AWS Athena, or Redshift Spectrum whose cost is tied to the total data scanned by queries. When you are billed by the computational capacity purchase as in Snowplow and Redshift, you may be shielded from such incidents, but your DWH performance gets severely impacted by costly queries.
- How can we avoid receiving unexpectedly expensive bills from the BigQuery/Athena/Redshift Spectrum?
- How can we keep our queries efficient so we don’t need to increase the over cost from DWH and operational inefficiency?
This article introduces basic ideas that help you avoid the blowup and lower the overall cost.
Enforcing partitions to the raw tables
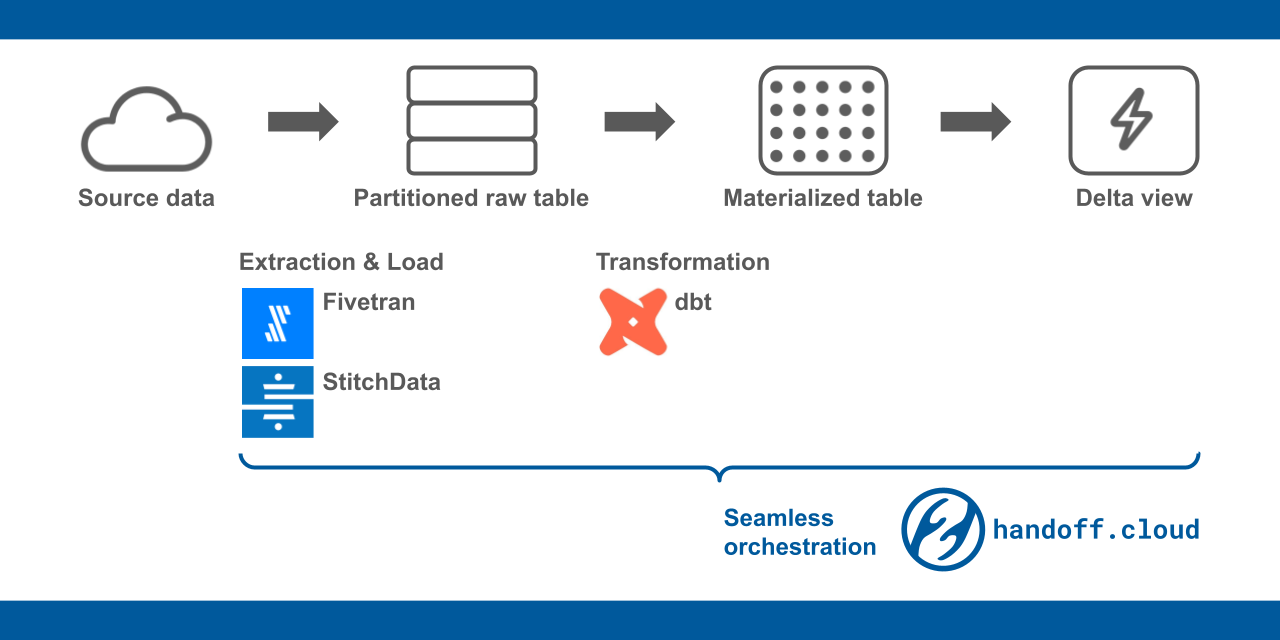
The first thing you can do is to enforce partitions on the raw tables. The big tables are almost always tied to the day-to-day ingestion of the raw data. The DWH can internally divide the big data into chunks, typically based on one of the timestamp columns in the table. The smaller chunks in the table are called partitions.
When you scan the partition with a specific range of timestamps, DWH scans only the partitions that fall into the range. That way, your query finishes fast with smaller data scanned. In most DWHs, you can set up to make the timestamp range always required by query to avoid scanning the entire table by accident.
Note: If you are a BigQuery user, ANELEN’s target-bigquery-partition loader does this automatically. We can also help you set up partitions for other DWHs. Just let us know by dropping an email to hello@handoff.cloud.
Set up materialized tables
The raw tables are cleaned and aggregated before they are put to use. You may be doing so by defining SQL views. Such views may be hooked to your dashboard. So, every time someone opens the dashboard, the DWH may be executing a query through the views.
You should pay extra attention to this if you are using dbt which encourages the use of views by design. Unless the view is configured to be automatically “materialized”, or to cache the query result for the repeated requests, the view is tapping on the raw data each time someone sends the query. This could also cause a higher cost and performance issue.
One explicit way of avoiding the costly scanning of raw tables is to periodically replicate the view result into a separate table. Let’s call it materialized table. If your dashboard just needs daily updates, you can run a job to refresh the materialized table. Some DWHs such as BigQuery have schedule features so you don’t have to do it manually. Otherwise, you can define a job in Airflow or dbt cloud.
Use delta view to get fresh data efficiently
One problem with the above approach is data freshness. Say, your data extractor (StitchData, Fivetran, Airflow, etc) pulls data from the source every hour but materialization happens daily basis. By accessing the materialized table, you only get yesterday’s metrics and of course, you want to peek at today’s intra-day progress. The so-called delta view will help you achieve that.
A delta view combines the raw data and the materialized table to synthesize the most recent data efficiently. First, it pulls out the pre-aggregated data from the materialized table. Then it checks the latest timestamp of the pulled data. Using the timestamp, it pulls the “delta” by scanning the raw table with the timestamp. This way, the delta view utilizes the best of both the raw table and the materialized table.
Here is an example dbt macro of delta view. The script also de-duplicates the rows based on the primary keys and the replication timestamp:
1 | {% macro events_delta( |
You can use this delta view definition to update the materialized table. Then the updated materialized table is referred to by the delta view next time someone wants the up-to-date data.
Seamlessly run extraction and materialization
Delta view works by coordinating data extraction and materialization. You may do so by:
- Schedule data extraction by StitchData, Fivetran, or create a task in Airflow.
- Define delta views. We recommend managing it with dbt with a macro like in the example above.
- Schedule the materialization by DWH’s scheduling feature if available or set up a job by yourself.
These steps may sound complex and the efficient coordination between the schedules at Step 1 & 3 could be tricky.
Note: handoff.cloud can run all 3 steps together whenever the data is replicated. This seamless delta view process resolves the coordination issues and generates the most up-to-date data with the lowest query cost. Plus, our fully customizable service can integrate data from the applications not supported by existing connectors in the market. We can also support more complex ELT logic and custom transformations. Learn more at handoff.cloud
Conclusion
As your data and team grow bigger, the query cost and efficiency become a headache to analytics managers. The use of a partitioned table and the materialized table save you DWH cost and increase the cluster efficiency. Delta views are an efficient way of pulling up-to-date metrics while keeping the query cost low.